
Introduction to LLM Leaderboards
An LLM leaderboard typically refers to a ranking system for evaluating and comparing different language models. LLM leaderboards are often used in the field of natural language processing to benchmark and assess the performance of different language models (such as OpenAI’s GPT models) on various NLP tasks. These tasks may include text generation, language understanding, translation, sentiment analysis, question answering, and more.
Leaderboards typically rank models based on their performance on multiple-choice benchmark tests and crowdsourced A/B preference testing. Sometimes, leaderboards will also use LLMs (such as GPT-4) to evaluate other LLMs. These tactics are used to assess the models’ capabilities, providing insights into which models perform best on different tasks or datasets.
LLM leaderboards play a crucial role in advancing the field of NLP by fostering competition, encouraging model development, and providing a standardized framework for comparing the performance of different language models. They also help researchers and practitioners identify state-of-the-art models and track advancements in the field over time.
Some of the most popular LLM leaderboards are those on Hugging Face, MMLU, AlpacaEval, MT-Bench, and ChatbotArena.
Are LLM Leaderboards Misleading?
Oftentimes, published leaderboards are taken at face value by practitioners who are using these benchmark rankings to guide them in model selection. However, recent research indicates that it can be dangerous to rely on simple benchmark evaluations that may lack the robustness required to mirror the complexity of real-world use.
Their research found that mildly changing the order in which questions are asked, or the order in which multiple-choice answer options are presented, can have large impacts on which LLMs are at the top of big leaderboards. Too often, evaluation is happening on the basis of bespoke multiple-choice tests instead of application-specific end-to-end user testing of the system in which an LLM is embedded.
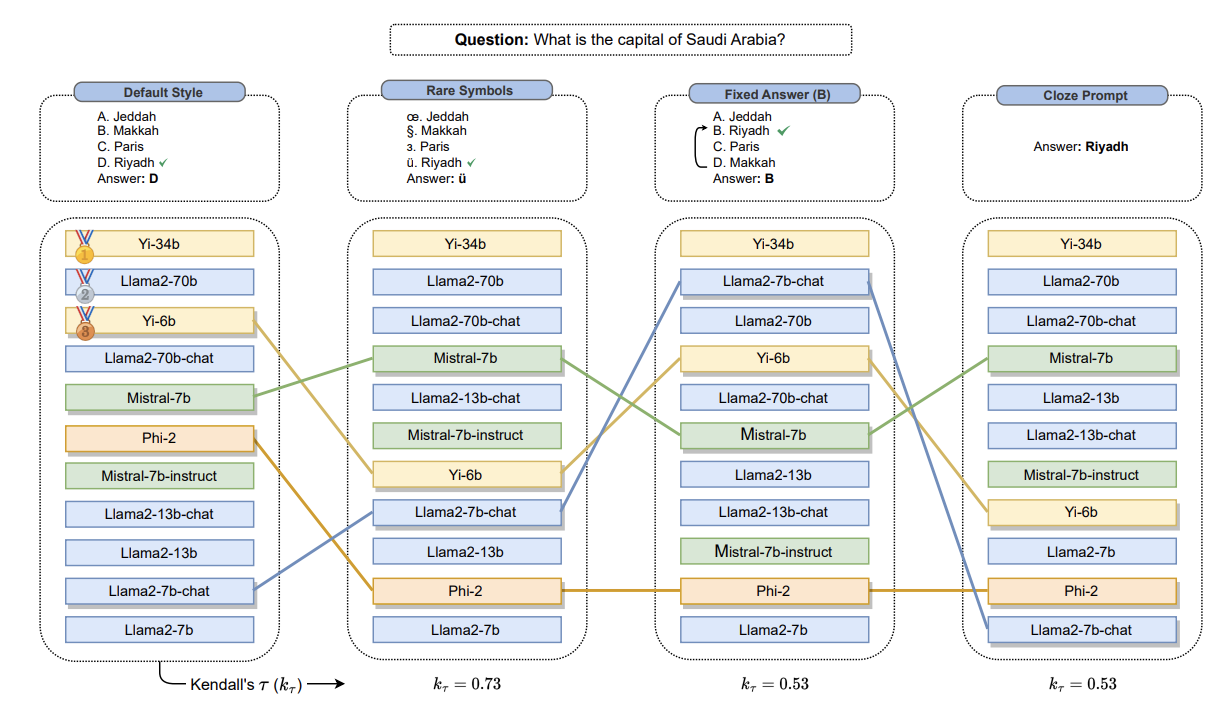
Another recent finding was about the LMSYS leaderboard. This leaderboard asks people to vote, in thousands of A/B test comparisons, on which LLM out of two options did better at a prompt (e.g. GPT-4 vs. Claude 2; Mistral vs. GPT-3.5-turbo; Claude 2 vs. LLaMa-70b; etc.). Recently, it was discovered that people’s votes in the A/B testing were extremely biased by the length of an LLM response (a finding that was also acknowledged by the maintainers of the AlpacaEval leaderboard). This means that the leaderboards may not really be showing which LLMs gave better answers, but rather which LLMs gave longer answers.
Why Might They Be Misleading?
Brittle Multiple-Choice Tests
As mentioned previously and shown in the figure above, multiple-choice tests can be brittle. Even something as simple as changing the order of the responses can significantly change LLM scores on benchmark tests.
Biased Human Voting
Whether consciously or subconsciously, we know that humans are often biased. A human might show bias toward responses that look better, for example, even if they aren’t actually more correct.
Data Contamination
Many LLMs may in fact be trained on data that is the same as—or highly similar to—these benchmarks. When a model is trained on data that contains test data, it can memorize the test examples and simply repeat them when prompted.
Therefore, the model might perform very well on the benchmark despite lacking a solid understanding of the underlying task, which would mean its high score is not necessarily indicative of how the model will perform in new scenarios. Additional research on this topic can be found in this paper as well as this one.
How Can We Fix This?
As we’ve noted throughout this post, benchmarks are not perfect. They can be biased, and they may not cover all of the potential applications of an LLM.
One way to fix this is to build task-specific benchmarks. Many LLM leaderboards provide a general overview of model performance, but it’s impossible to truly understand how effective an LLM might be for your specific use case without task-specific benchmarks.
On a recent panel at Arthur HQ, Andriy Mulyar, co-founder and CTO of Nomic, noted that “everyone should be really focused not on building models, but on building very good task-specific benchmarks that are internal to the specific use case—and then working back on the actual modeling once they’ve defined very clearly how they want to actually test their model in a dev environment.”
Raz Besaleli, co-founder and Director of AI Research at Seek AI, agreed that the “leaderboardization” of evaluations is often insufficient. “When you’re building a product,” they noted, “often the task that you’re trying to solve is a lot more specific than what these leaderboards do. [...] Not only should you have very task-specific benchmarks, but you should have a whole suite of them.”
Conclusion
In general, evaluating large generative language systems is a difficult and complex problem that currently lacks a clear solution. Whether you believe leaderboards are helpful, harmful, or somewhere in between, determining the performance levels of these models will continue to be an evergreen problem in this nascent space, and we at Arthur look forward to seeing how the frontier of evaluation develops.
Interested in learning more about LLM evaluation? Check out Arthur Bench.
FAQ
How do LLM leaderboards account for updates or improvements in LLMs and other AI models over time?
LLM leaderboards typically adapt to updates or improvements in language models by periodically refreshing their datasets and evaluation methods to reflect the latest advancements in AI and ML technology. They include the most recent versions of language models, updating benchmarks to challenge new features and capabilities, thereby ensuring that the leaderboards accurately reflect the current landscape of LLM and ML advancements. This process helps maintain the relevance and accuracy of AI model comparisons, fostering a competitive environment for continuous improvement in the field of natural language processing.
What are the specific criteria or metrics used to rank LLMs on these AI and ML leaderboards?
The specific criteria or metrics used to rank LLMs on AI and ML leaderboards usually encompass a range of performance indicators tailored to assess the depth and breadth of machine learning models' language abilities. These metrics, central to evaluating AI advancements, might include accuracy, fluency, and context-awareness, alongside more nuanced measures such as the ability of LLMs to generate coherent and contextually relevant responses. These criteria are crucial for benchmarking the progress and effectiveness of ML models in various NLP tasks, providing a structured framework to compare and improve AI technologies.
How do developers or researchers in the AI and ML fields address the issue of data contamination in LLM training beyond avoiding training on benchmark data?
In the AI and ML fields, developers and researchers tackle the issue of data contamination in LLM training by implementing a variety of strategies beyond merely avoiding benchmark data during training. These include employing advanced data processing techniques to ensure the integrity and diversity of training materials, applying domain adaptation methods to enhance the LLM's ability to generalize across different contexts, and conducting rigorous testing to detect and mitigate biases. These practices are essential for developing robust, effective ML models that perform well across a wide range of AI-driven tasks and scenarios, ensuring that LLMs deliver reliable and unbiased outcomes.
SHARE



